Stephanie Birkelbach

Howdy! I'm an undergraduate student at Texas A&M University pursuing dual Bachelor of Science degrees in Computer Science and Statistics!
I am interested in how computing can help us understand people and society. I enjoy exploring topics within computational social science, human-centered NLP, HCI, or more generally, solving interesting human problems. Ultimately, I hope to contribute to ethical and socially beneficial technology.
Social Computing & Cultural AI Systems
AI systems respond differently to different people — shaped by signals of identity like gender, accent, and voice, and signals of expression like creativity and discourse. This work examines how social, cultural, and platform-level contexts influence model behavior and system outcomes, with the goal of designing language technologies that better align with the communities, norms, and narratives in which they are deployed.
|
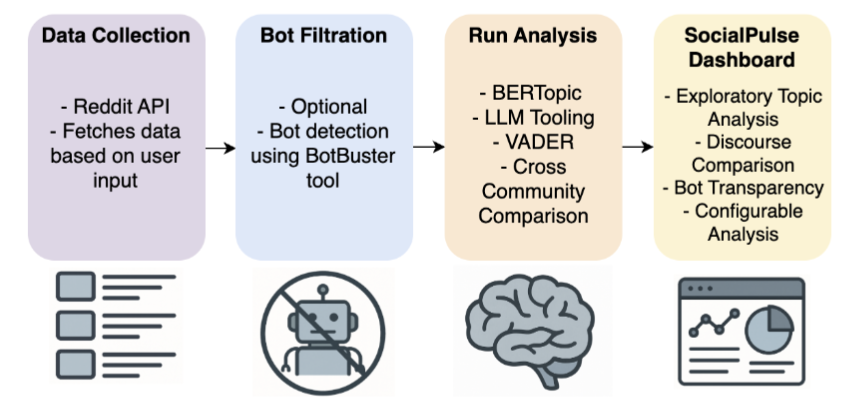
SocialPulse: An Open-Source Subreddit Sensemaking Toolkit Stephanie Birkelbach, Maria Teleki, Peter Carragher, Xiangjue Dong, Nehul Bhatnagar, James Caverlee Collaboration w/ Carnegie Mellon University, Revionics SocialLLM@ICWSM 26 Presented at IC2S2 (Oral)
Understanding how online communities discuss and make sense of complex social issues is a central challenge in social media research, yet existing tools for large-scale discourse analysis are often closed-source, difficult to adapt, or limited to single analytical views. We present SocialPulse, an open-source subreddit sensemaking toolkit that unifies multiple complementary analyses -- topic modeling, sentiment analysis, user activity characterization, and bot detection -- within a single interactive system. SocialPulse enables users to fluidly move between aggregate trends and fine-grained content, compare highly active and long-tail contributors, and examine temporal shifts in discourse across subreddits. The demo showcases end-to-end exploratory workflows that allow researchers and practitioners to rapidly surface themes, participation patterns, and emerging dynamics in large Reddit datasets. By offering an extensible and openly available platform, SocialPulse provides a practical and reusable foundation for transparent, reproducible sensemaking of online community discourse.
@inproceedings{birkelbach26_socialpulse,
|
|
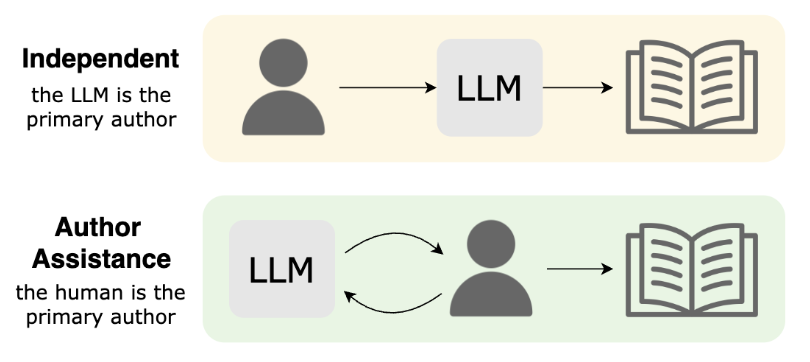
A Survey on LLMs for Story Generation Maria Teleki, Xiangjue Dong, Peter Carragher, Vedangi Bengali, Tian Liu, Haoran Liu, Sai Tejas Janjur, Thomas Docog, Stephanie Birkelbach, Oliver Grabner, Cong Wang, Ting Liu, Yin Zhang, Frank Shipman, James Caverlee Collaboration w/ Carnegie Mellon University EMNLP Findings 2025
Methods for story generation with Large Language Models (LLMs) have come into the spotlight recently. We create a novel taxonomy of LLMs for story generation consisting of two major paradigms: (i) independent story generation by an LLM, and (ii) author-assistance for story generation -- a collaborative approach with LLMs supporting human authors. We compare existing works based on their methodology, datasets, generated story types, evaluation methods, and LLM usage. With a comprehensive survey, we identify potential directions for future work.
@inproceedings{teleki25_survey,
|
Disfluency-Aware Speech and Language Understanding
Current speech and language understanding systems are built for fluent text, not for how people actually speak. Disfluencies -- pauses, repairs, hedges, and restarts -- are treated as artifacts to be removed, despite being fundamental to spoken communication. My work challenges this assumption by modeling disfluency as meaningful linguistic structure. I develop models, benchmarks, and evaluation frameworks that operate directly on spontaneous speech, yielding more robust language understanding in real-world conversational settings.

|
Z-Scores: A Metric for Linguistically Assessing Disfluency Removal Maria Teleki, Sai Janjur, Haoran Liu, Oliver Grabner, Ketan Verma, Thomas Docog, Xiangjue Dong, Lingfeng Shi, Cong Wang, Stephanie Birkelbach, Jason Kim, Yin Zhang, James Caverlee ICASSP 2026
Evaluating disfluency removal in speech requires more than aggregate token-level scores. Traditional word-based metrics such as precision, recall, and F1 (E-Scores) capture overall performance but cannot reveal why models succeed or fail. We introduce Z-Scores, a span-level linguistically-grounded evaluation metric that categorizes system behavior across distinct disfluency types (EDITED, INTJ, PRN). Our deterministic alignment module enables robust mapping between generated text and disfluent transcripts, allowing Z-Scores to expose systematic weaknesses that word-level metrics obscure. By providing category-specific diagnostics, Z-Scores enable researchers to identify model failure modes and design targeted interventions -- such as tailored prompts or data augmentation -- yielding measurable performance improvements. A case study with LLMs shows that Z-scores uncover challenges with INTJ and PRN disfluencies hidden in aggregate F1, directly informing model refinement strategies.
@inproceedings{teleki25_zscores,
|
|
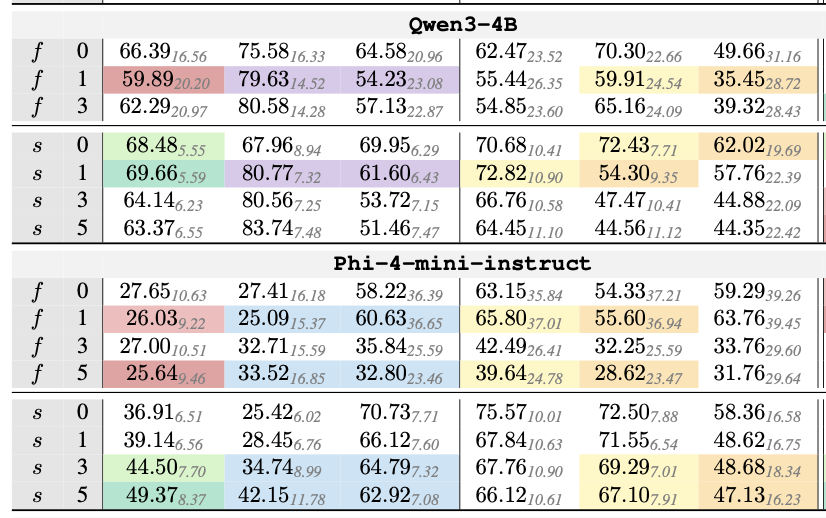
Conversational Speech Reveals Structural Robustness Failures in SpeechLLM Backbones Maria Teleki, Sai Janjur, Haoran Liu, Oliver Grabner, Ketan Verma, Thomas Docog, Xiangjue Dong, Lingfeng Shi, Cong Wang, Stephanie Birkelbach, Jason Kim, Yin Zhang, Éva Székely, James Caverlee Collaboration w/ KTH Royal Institute of Technology Preprint 2026
LLMs serve as the backbone in SpeechLLMs, yet their behavior on spontaneous conversational input remains poorly understood. Conversational speech contains pervasive disfluencies -- interjections, edits, and parentheticals -- that are rare in the written corpora used for pre-training. Because gold disfluency removal is a deletion-only task, it serves as a controlled probe to determine whether a model performs faithful structural repair or biased reinterpretation. Using the DRES evaluation framework, we evaluate proprietary and open-source LLMs across architectures and scales. We show that model performance clusters into stable precision-recall regimes reflecting distinct ``editing policies.'' Notably, reasoning models systematically over-delete fluent content, revealing a bias toward semantic abstraction over structural fidelity. While fine-tuning achieves SOTA results, it harms generalization. Our findings demonstrate that robustness to speech is shaped by specific training objectives.
@inproceedings{teleki26_dres,
|